Project Overview
This project compares the performance of different reinforcement learning algorithms at playing Slime Volleyball—a 2D volleyball game where the objective is to get the ball to land on the opponent's side of the net.
We used the SlimeVolleyGym environment to test multi-agent RL algorithms and have different agents compete in the same environment. The environment has a simple reward structure: +1 if the ball lands on the opponent's side, -1 if it lands on the agent's side.
Key Metrics:
- Average reward over 1000+ episodes against baseline
- Win rate comparison between algorithms
- Learning stability and convergence analysis
- Maximum score of 5 per episode (first to 5 wins)
Algorithm Implementations
Deep Q-Network (DQN)
Uses a deep neural network to approximate Q-values, eliminating the need for a Q-table in the continuous 12-dimensional state space. Implemented with experience replay and Double Q-Learning to reduce overestimation.
Cross-Entropy Method (CEM)
A population-based evolutionary approach that iteratively updates parameters based on elite samples. Generates policy populations, evaluates performance, and updates distributions based on top performers.
Advantage Actor-Critic (A2C)
Combines policy-based and value-based learning with an actor network (selects actions) and critic network (estimates rewards). Uses synchronous updates for stable gradient computation.
Proximal Policy Optimization (PPO)
Improves upon policy gradient methods by limiting updates within a "trust region" using a clipped objective function. Our implementation includes curriculum learning and reward shaping.
Results & Analysis
Deep Q-Network Results
Despite the continuous state space challenges, DQN showed signs of learning. After 500 test games against the baseline, it achieved an average score of -4.4 with a standard deviation of 0.674.

DQN agent (yellow, right) playing against the baseline opponent
The agent learned that jumping often could lead to better performance, but struggled with ball tracking. Double Q-Learning implementation showed slight improvements in early exploration but similar late-stage performance.
Cross-Entropy Method Results
CEM struggled with the sparse reward structure and volatile gameplay. Training against the baseline showed minimal improvement, while self-play resulted in more stable learning with win rates hovering around 50%.
CEM agent attempting to play against the baseline opponent
The stochastic parameter updates made it difficult to develop structured strategies, especially with delayed rewards over extended interactions.
A2C Results
Training against the baseline for 1,000 episodes showed almost no improvement, with rewards staying close to -5. Self-play for 5,000 episodes resulted in better gameplay behavior with more natural movements and improved ball control.

A2C agent trained with self-play showing improved movement patterns
However, even the self-play trained model couldn't consistently beat the baseline opponent, suggesting self-play alone may not prepare agents for strong opponents.
PPO Results (Best Performer)
PPO demonstrated the most effective learning, achieving a final win rate of approximately 78-80% against the baseline agent. PPO with Intrinsic Motivators (PPO-IM) showed even greater stability.
Standard PPO Performance
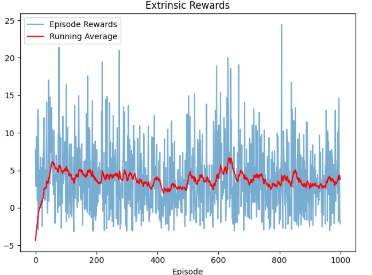
PPO extrinsic rewards over 1000 episodes showing steady improvement
PPO with Intrinsic Motivators
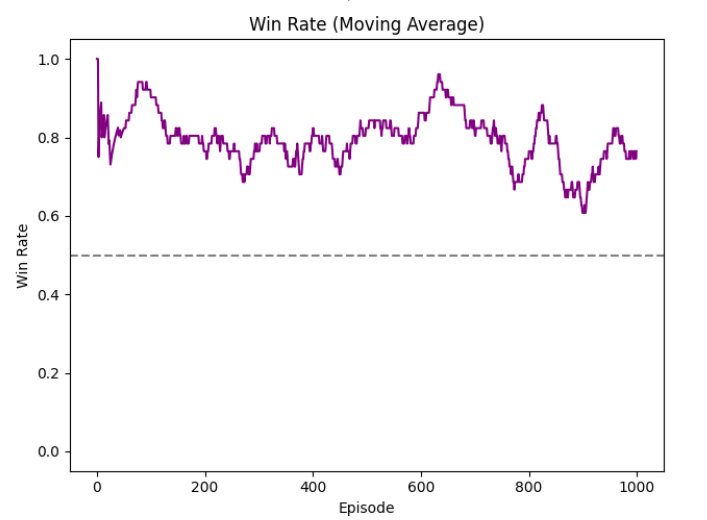
PPO-IM win rate stabilizing around 80%
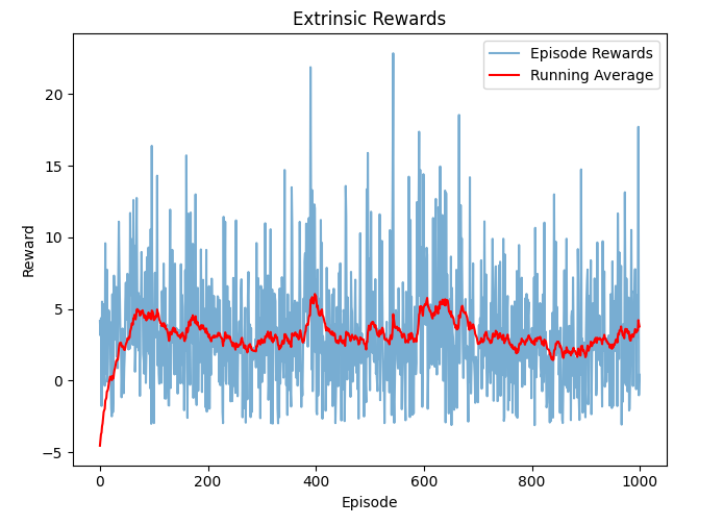
PPO-IM extrinsic rewards showing consistent performance
| Metric | PPO | PPO-IM |
|---|---|---|
| Final Win Rate | ~78% | ~80% |
| Final Avg Reward | ~3.9 | 4-5 |
| Exploration Stability | Decreased over time | More stable |
| Entropy Trends | Decreased sharply | Gradual decrease |
The intrinsic reward mechanism helped maintain balanced exploration, leading to more consistent policy updates and improved long-term performance.
Key Innovations
Curriculum Learning
Gradually increased difficulty by adjusting ball speed from 70% to 100% over training episodes, allowing agents to learn more easily at the beginning.
Reward Shaping
Added small survival bonuses and rewards for beneficial actions like hitting the ball, addressing the sparse reward problem in the original environment.
Intrinsic Motivation
Implemented curiosity-driven exploration with intrinsic rewards based on the agent's ability to predict state transitions, encouraging exploration of unfamiliar states.
Self-Play Training
Trained agents against past versions of themselves, allowing dynamic adaptation as both sides improved over time.
Conclusions
The main takeaway is that PPO outperformed all other algorithms, demonstrating effective learning and maintaining a high win rate against the baseline. The addition of intrinsic motivators further improved stability and adaptability.
Key Findings:
- DQN struggles with continuous state spaces but shows learning potential with more episodes
- CEM's stochastic updates make it unsuitable for environments with sparse, delayed rewards
- A2C benefits from self-play but may overfit to a single playstyle
- PPO with curriculum learning and reward shaping achieves the best performance
- Intrinsic motivation mechanisms improve exploration balance and long-term learning
Future work could explore Dueling DQN, Rainbow DQN, and training against diverse opponents to develop more adaptable strategies.