Project Overview
A full-stack AI-powered product recommendation engine built with a FastAPI async backend and a React 18 frontend with lazy-loaded components. Every request goes through a 3-stage pipeline: hard preference filtering, 384-dimensional vector similarity search, and GPT re-ranking. If the OpenAI API isn't reachable, a priority-bucket rule-based fallback takes over automatically.
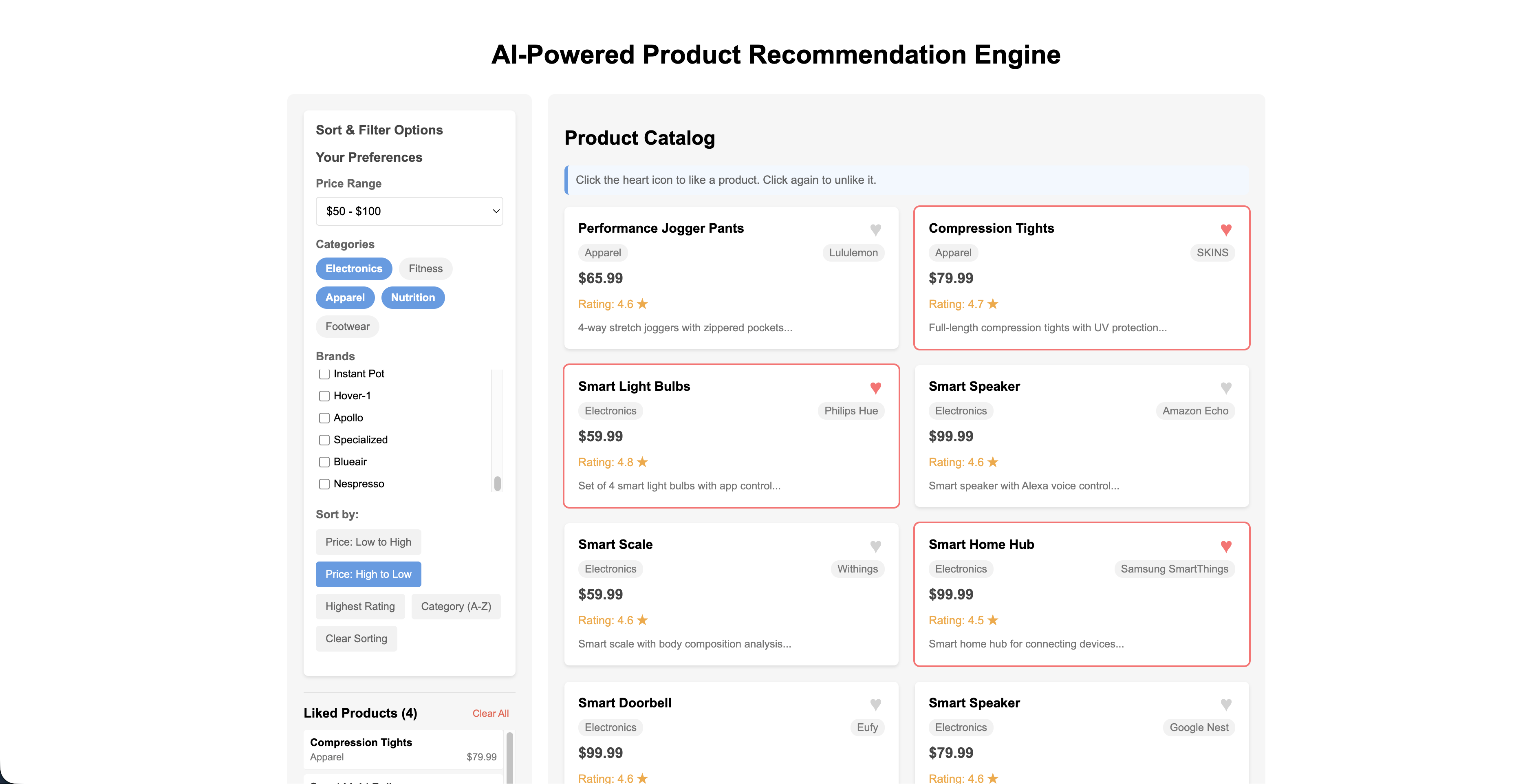
The main dashboard: filter by price, category, and brand on the left; like products from the catalog on the right.
Works without an API key: the vector search pipeline runs entirely locally via sentence-transformers on Apple Silicon. GPT only handles the final re-ranking step. If the key is missing, rate-limited, or returns bad JSON, the system automatically falls back to a rule-based ranker that always returns 3 results.
How It Works
Every POST /api/recommendations request passes through this 3-stage pipeline:
The full 125-product catalog is scanned. Any product is excluded if its ID matches a liked product, it falls outside the user's price range, its category isn't in the user's preferred categories, or its brand isn't in the user's preferred brands. Both subsequent stages operate only on this filtered subset, so hard constraints are always respected before any AI logic runs.
Each liked product's name + description + category is encoded into a 384-dimensional embedding using all-MiniLM-L6-v2 (sentence-transformers, running on Apple Silicon MPS). These embeddings are averaged into a single query vector representing the user's overall taste profile. Cosine similarity is computed against every filtered product's pre-indexed embedding, returning the top 10 semantically closest candidates. The full 125-product embedding matrix is computed once at startup and reused on every request.
The 10 vector candidates enter one of two paths:
A prompt with the user's liked products, preferences, and the 10 candidates is sent to gpt-4o-mini via AsyncOpenAI. GPT picks the best 3 and writes a personalized explanation for each: "Since you liked X, you'll love Y because..."
Triggered by APIConnectionError, RateLimitError, AuthenticationError, APIStatusError, or invalid/empty GPT JSON. Candidates are sorted into priority buckets and selected with a two-pass algorithm that tries to vary categories before relaxing that constraint.
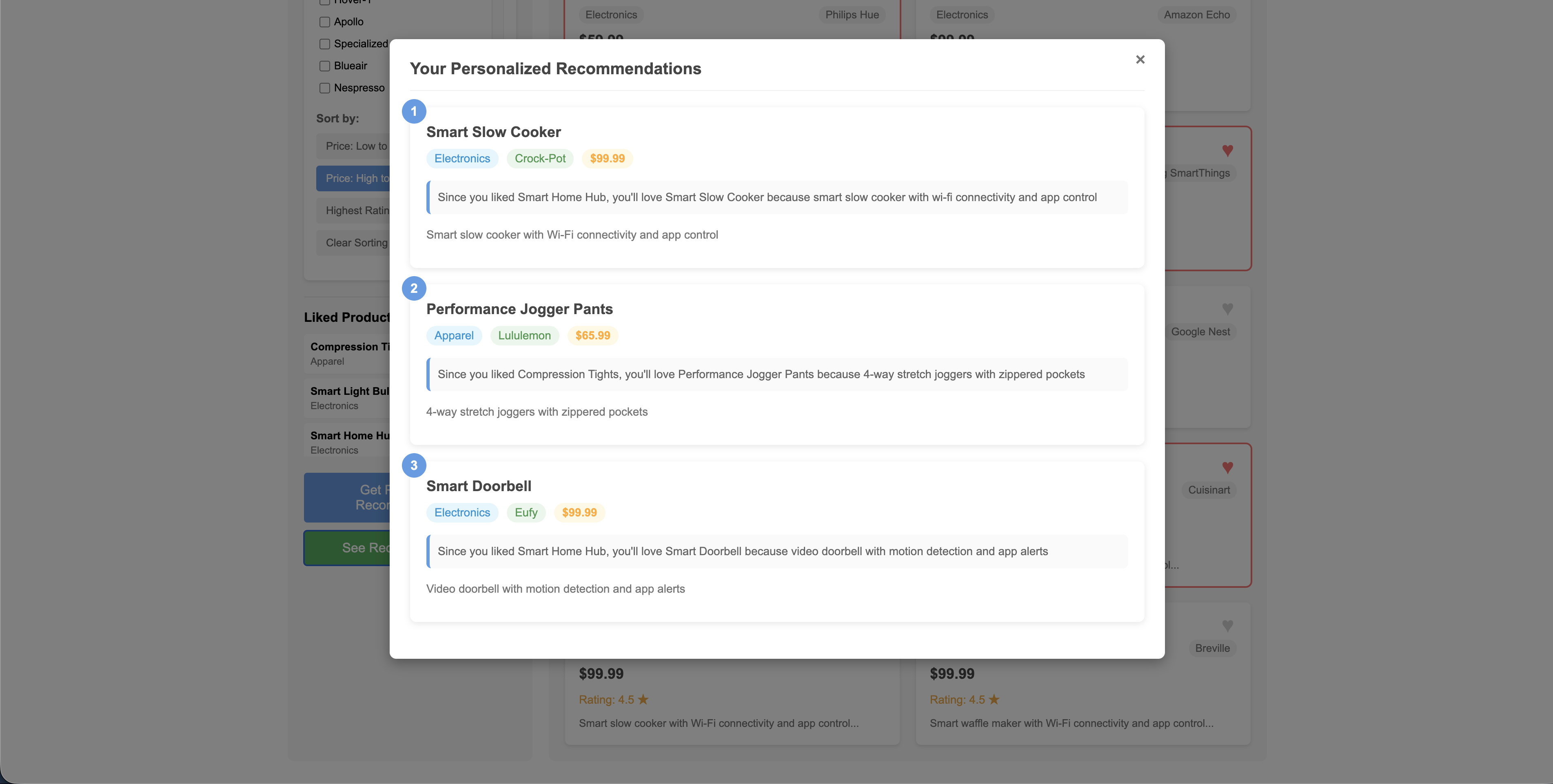
The recommendations modal showing GPT-generated explanations: "Since you liked Smart Home Hub, you'll love Smart Slow Cooker because..."
Rule-Based Fallback Detail
When GPT is unavailable, the 10 vector candidates are sorted into 5 priority buckets:
| Priority | Bucket | Condition |
|---|---|---|
| 1 | preferred_pool | Category matches user's explicit category filter |
| 2 | same_category | Category matches a liked product's category |
| 3 | same_brand | Brand matches a liked product's brand |
| 4 | complementary | Category is in the hardcoded complementary map (e.g. Electronics → Accessories, Sports → Health) |
| 5 | other | Everything else |
A two-pass selection guarantees 3 results. The first pass iterates buckets in priority order and enforces category variety by skipping any product whose category is already represented until 2 picks are made. The second pass drops the variety rule and fills up to 3 from whatever is left. Each result gets a generated explanation linking it to a liked product in the same category or brand.
Tech Stack
| Layer | Technology |
|---|---|
| Backend | Python 3.10, FastAPI, Uvicorn |
| AI / Embeddings | sentence-transformers (all-MiniLM-L6-v2), PyTorch with MPS on Apple Silicon |
| LLM | OpenAI gpt-5-mini via AsyncOpenAI |
| Data | 125-product JSON catalog (products_extended.json) |
| Frontend | React 18, lazy loading via React.lazy + Suspense |
| Validation | Pydantic v1 |
Project Structure
AI-RecommenderSystem/
├── backend/
│ ├── app.py # FastAPI routes, service wiring
│ ├── config.py # Environment config
│ ├── requirements.txt
│ ├── .env.example
│ ├── data/
│ │ └── products_extended.json # 125-product catalog
│ ├── services/
│ │ ├── vector_service.py # Embedding index + cosine similarity search
│ │ ├── llm_service.py # GPT re-ranking + rule-based fallback pipeline
│ │ └── product_service.py # Product data access
│ └── tests/
│ └── test_recommendations.py
└── frontend/
└── src/
├── App.js # Main component, lazy-loaded children
├── components/
│ ├── Catalog.js
│ ├── Recommendations.js
│ ├── UserPreferences.js
│ └── BrowsingHistory.js
└── services/
└── api.jsApp Startup
On python app.py, three things happen once before any requests are served:
ProductService
Loads products_extended.json into 125 Product objects in memory.
VectorService: model load and catalog indexing
all-MiniLM-L6-v2 (~80 MB) is downloaded on first run and then cached. VectorService.index_catalog() encodes every product's name + description into a 384-dimensional embedding tensor. This matrix is computed once and reused for every request, so startup costs about 2-3 seconds on first run and subsequent starts are fast.
LLMService
Instantiated with a reference to VectorService. If OPENAI_API_KEY is present in .env, an AsyncOpenAI client is created. If not, self.client = None and every request routes directly to the rule-based fallback.
Key Design Decisions
- Pre-filtered vector search: Hard preference constraints are applied before similarity search, not after. This ensures GPT and the fallback only ever see eligible candidates.
- Mean embedding query: Liked product embeddings are averaged into one query vector, giving a single semantic representation of the user's full taste profile rather than running multiple searches.
- Startup indexing: The 125-product embedding matrix is computed once at server startup and reused for every request, keeping per-request latency low.
- Two-pass mock selection: The first pass enforces category variety; the second pass relaxes it. This guarantees 3 results are always returned, even when all 10 candidates share a single category.
- Typed exception fallback: Only specific OpenAI exception types trigger the fallback (
APIConnectionError,RateLimitError,AuthenticationError,APIStatusError), not a broadexcept Exception. This avoids silently swallowing unexpected bugs. - Invalid JSON also triggers fallback: If GPT returns unparseable JSON or hallucinates product IDs not in the 10 candidates, the parse returns empty and the rule-based path runs automatically.
Source Code
Full source code, backend services, and frontend components are available on GitHub:
View on GitHub